
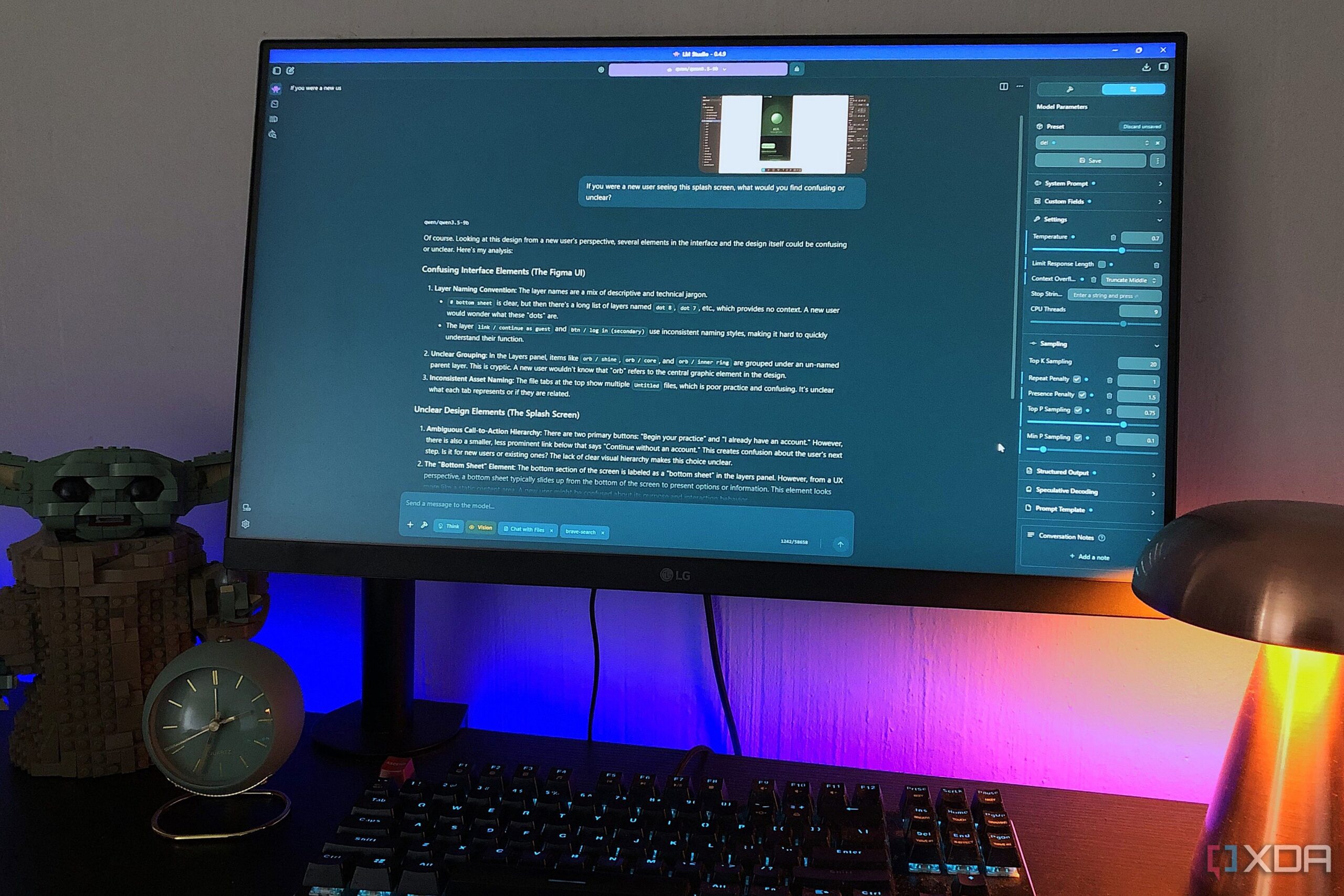
دوامة التحديثات: تحدي موثوقية نماذج اللغة الكبيرة المستضافة ذاتيًا
في رحلةٍ دائمة نحو تحسين الأداء وتعزيز الموثوقية، يجد الكثير من عشاق التكنولوجيا أنفسهم عالقين في دوامةٍ مستمرة من التحديثات والاختبارات عند تشغيل نماذج اللغة الكبيرة (LLMs) المستضافة ذاتيًا. هذه العملية، التي تبدو في ظاهرها سعيًا طبيعيًا نحو الأفضل، تتحول سريعًا إلى تحدٍ حقيقي يستنزف الوقت والجهد. فالحل لا يكمن دائمًا في التحديث الأكبر أو النموذج الأحدث، بل في فهم أعمق لديناميكيات هذه التقنيات المعقدة.
تُظهر التجربة أن هذا المسار لا يقتصر على مجرد تحميل إصدارات جديدة، بل يتعداه إلى مقارنات دقيقة بين المعايير المختلفة، في سعيٍ حثيث لتحقيق الاستقرار والأداء الموثوق به في بيئات التشغيل الشخصية.
رحلة البحث عن الموثوقية: تحديات متجددة
إن عملية تشغيل نماذج اللغة الكبيرة المستضافة ذاتيًا (Self-Hosted LLMs) ليست بالبساطة التي قد يتصورها البعض؛ فما يبدأ كمسعى لتحقيق الكفاءة والمرونة ينتهي غالبًا بدوامةٍ لا متناهية من التحديثات والاختبارات. يجد المستخدم نفسه مضطرًا لتجربة إصدارات جديدة من النماذج الكمية (quants)، وهي نسخ مُحسنة من النماذج الأصلية تهدف إلى تقليل استهلاك الموارد دون التأثير بشكل كبير على الأداء. هذه العملية تتطلب جهدًا كبيرًا في المتابعة والتقييم المستمر.
لكن التحدي الأكبر يكمن في مقارنة معايير الأداء المختلفة؛ فليس فقط جودة الإجابات هي ما يهم، بل أيضًا عوامل مثل أطوال السياق التي يمكن للنموذج التعامل معها، وكفاءته في استهلاك ذاكرة الوصول العشوائي للفيديو (VRAM). كل هذه العناصر تتطلب مراقبة دقيقة واختبارات متكررة لضمان أن النموذج يعمل بالشكل الأمثل ضمن إعدادات الجهاز المتاحة، وهو ما يحول التجربة إلى سعيٍ دائم نحو تحقيق الموثوقية المنشودة.
تجارب شخصية: دوامة التحديثات التي لا تنتهي
بالنسبة للكثيرين ممن خاضوا هذه التجربة، فإنها تتجاوز مجرد التحديات التقنية لتصبح رحلةً شخصية من الإحباط والتعلم. يصف أحد الخبراء تجربته قائلاً:
لقد مررت بهذه المرحلة بالضبط؛ حيث كان كل تحدٍ يواجهني يبدو وكأنه مشكلة في الأجهزة أو في جودة النموذج، تنتظر الحل بتحميل أكبر.
هذا الاقتباس يلخص بدقة شعور العديد من المستخدمين الذين يعتقدون أن الحل لأي مشكلة يواجهونها يكمن في تحديث أكبر أو نموذج أحدث. لكن الواقع غالبًا ما يكون مختلفًا، فالمشكلة قد لا تكون في الأجهزة أو في جودة النموذج بحد ذاتها، بل في عدم التوافق بين هذه المكونات أو في عدم فهم دقيق لكيفية عمل النموذج في بيئة معينة. هذا الاعتقاد يدفع المستخدمين إلى دورة لا نهائية من التحديثات، على أمل أن يكون التحديث القادم هو الحل السحري الذي سيجلب الاستقرار والموثوقية.
معايير الأداء: أكثر من مجرد أرقام
عند الحديث عن نماذج اللغة الكبيرة، لا يمكن حصر معايير الأداء في مجرد أرقام مجردة. فالأمر يتعدى سرعة الاستجابة أو دقة الإجابات ليشمل جوانب حيوية أخرى تؤثر بشكل مباشر على تجربة المستخدم وكفاءة النظام ككل. على سبيل المثال، تعتبر أطوال السياق (context lengths) التي يمكن للنموذج معالجتها عاملًا حاسمًا في تحديد قدرته على فهم المحادثات الطويلة والمعقدة أو تحليل النصوص الكبيرة. فكلما زادت قدرة النموذج على التعامل مع سياقات أطول، زادت فعاليته في المهام التي تتطلب فهمًا عميقًا للمعلومات.
بالإضافة إلى ذلك، يُعد استهلاك ذاكرة الوصول العشوائي للفيديو (VRAM) مؤشرًا حيويًا على كفاءة النموذج، خاصةً عند تشغيله على أجهزة ذات موارد محدودة. فالنماذج التي تستهلك VRAM أقل يمكن تشغيلها على نطاق أوسع من الأجهزة، مما يقلل من الحواجز التقنية أمام تبنيها. وبالتالي، يصبح الهدف من كل عملية تحديث واختبار هو الموازنة بين هذه المعايير المختلفة، لتحقيق أقصى قدر من الموثوقية والاستقرار دون التضحية بالأداء أو الكفاءة.
الخلاصة: الموثوقية ليست وجهة بل رحلة
في نهاية المطاف، تُظهر تجربة إدارة وتحديث نماذج اللغة الكبيرة المستضافة ذاتيًا أن الموثوقية ليست وجهة يتم الوصول إليها بتحديث واحد، بل هي رحلة مستمرة من التعلم والتكيف والاختبار. إن السعي وراء نموذج مثالي يعمل بكفاءة تامة في جميع الظروف هو تحدٍ يتطلب صبرًا وفهمًا عميقًا للجوانب التقنية المختلفة. فكل تحديث يجلب معه فرصًا جديدة للتحسين، ولكنه أيضًا يفتح الباب أمام تحديات جديدة تتطلب حلولًا مبتكرة. إن فهم أن المشكلة قد لا تكون دائمًا في الأجهزة أو في جودة النموذج، بل في التفاعل المعقد بين هذه المكونات، هو الخطوة الأولى نحو الخروج من دوامة التحديثات اللانهائية وتحقيق الاستقرار المنشود في عالم الذكاء الاصطناعي سريع التطور.